| .gitea/workflows | ||
| calibre-db | ||
| little-hesinde | ||
| .containerignore | ||
| .gitignore | ||
| Cargo.lock | ||
| Cargo.toml | ||
| Containerfile | ||
| COPYING | ||
| deny.toml | ||
| flake.lock | ||
| flake.nix | ||
| README.md | ||
| screenshot.jpg | ||
{kind=link}
Little Hesinde
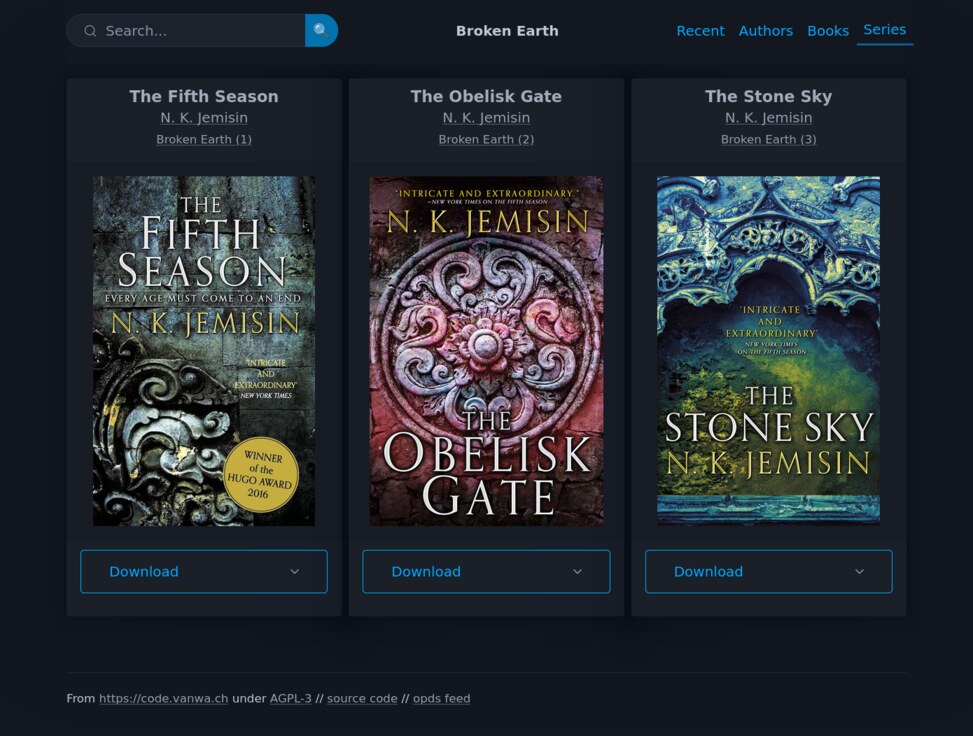
I have been a long time user of cops and its fork in order to access my ebook collection in a nice way from a browser. My biggest use always has been the ODPS feed for getting all of that from within KOReader.
It so happened that exactly when I was looking for a small side project I also had trouble with a new cops version (not through their fault, only because I insist on writing my own containers). How hard can it be I thought and went on hacking something together. The result does at most one tenth of what cops can do but luckily enough it is the part I need for myself.
Building
Nix
A nix environment with enabled
nix-commands in order to use nix develop.
Run nix develop to be dropped into a shell with everything installed and
configured. From there all the usual cargo commands are accessible.
Classic
A recent rust installation is all that is needed.
From there on cargo run and cargo build and so on can be used.
Configuration
Usage: little-hesinde [OPTIONS] -- <LIBRARY_PATH>
Arguments:
<LIBRARY_PATH> Calibre library path
Options:
-l, --listen-address <LISTEN_ADDRESS> Address to listen on [default: [::1]:3000]
-h, --help Print help
-V, --version Print version
Example: little-hesinde -l [::]4000 -- ~/Documents/library/
Usage
Run the binary with the calibre library as an argument and open http://localhost:3000 (or wherever it should be accessible). http://localhost:3000/opds is the entry point for the OPDS feed.
FAQ
No authentication?
Not planned, put a reverse proxy in front of it that handles access.
How do I search?
Putting in your search text and you are done. Searching is done on title, tags, author, series title, identifiers and comments.
For more sophisticated queries take a look at the fts5 documentation.
Why are the OPDS entries not paginated?
My hardware (a Kobo Aura One from ~2016) with KOReader works perfectly fine with parsing the 1MB book feed from my own library. Once that changes I might get over my laziness and implement it.
Aren't these database access patterns inefficient?
They most probably are but my elaborate testing setup (my own calibre library) works fine with it.
Why rust?
I like the language and wanted to try the poem framework.
Is it webscale?
Go away.